rocksdb(Leveldb)
Rocksdb源自于Leveldb,fork了Leveldb的代码后,facebook在Leveldb的基础上做了很多的改进,然后开源并重新命名为Rocksdb,leveldb和rocksdb一样,都是基于LSM-Tree思想所设计的
基本介绍
是一个key/value存储,key值根据用户指定的comparator排序。
特性
keys 和 values 是任意的字节数组。数据按 key 值排序存储。调用者可以提供一个自定义的比较函数来重写排序顺序。提供基本的 Put(key,value),Get(key),Delete(key) 操作。多个更改可以在一个原子批处理中生效。使用 Snappy 压缩库对数据进行自动压缩与外部交互的操作都被抽象成了接口(如文件系统操作等),因此用户可以根据接口自定义的操作系统交互。
LevelDb是一个持久化存储的KV系统,和Redis这种内存型的KV系统不同,LevelDb不会像Redis一样狂吃内存,而是将大部分数据存储到磁盘上。 LevelDb性能非常突出,官方网站报道其随机写性能达到40万条记录每秒,而随机读性能达到6万条记录每秒。总体来说,LevelDb的写操作要大大快于读操作,而顺序读写操作则大大快于随机读写操作。
架构图
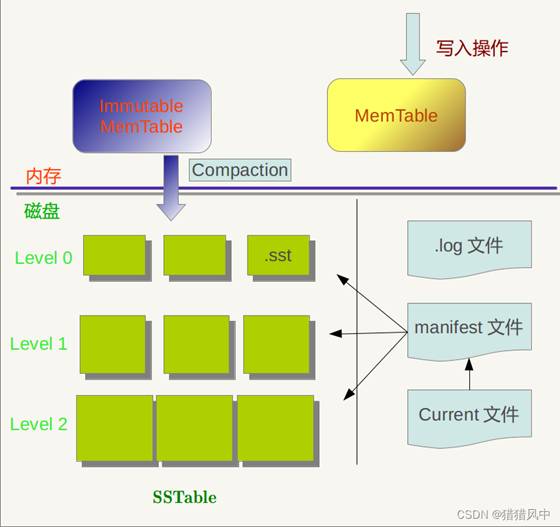
log文件、MemTable、SSTable文件都是用来存储k-v记录的,下面再说说manifest和Current文件的作用。SSTable中的某个文件属于特定层级,而且其存储的记录是key有序的,那么必然有文件中的最小key和最大key,这是非常重要的信息,Manifest 就记载了SSTable各个文件的管理信息,比如属于哪个Level,文件名称叫啥,最小key和最大key各自是多少。下图是Manifest所存储内容的示意:

另外,在LevleDb的运行过程中,随着Compaction的进行,SSTable文件会发生变化,会有新的文件产生,老的文件被废弃,Manifest也会跟着反映这种变化,此时往往会新生成Manifest文件来记载这种变化,而Current则用来指出哪个Manifest文件才是我们关心的那个Manifest文件
写操作流程:
1、顺序写入磁盘log文件;
2、写入内存memtable;
3、写入磁盘SST文件(sorted string table files),这步是数据归档的过程(永久化存储);
注意:
log文件的作用是是用于系统崩溃恢复而不丢失数据,假如没有Log文件,因为写入的记录刚开始是保存在内存中的,此时如果系统崩溃,内存中的数据还没有来得及Dump到磁盘,所以会丢失数据;
在写memtable时,如果其达到check point(满员)的话,会将其改成immutable memtable(只读),然后等待dump到磁盘SST文件中,此时也会生成新的memtable供写入新数据;
memtable和sst文件中的key都是有序的,log文件的key是无序的;
删除操作对于LevelDB也是插入,只是标记Key为删除状态,真正的删除要到Compaction的时候才去做真正的操作;
更新操作LevelDB没有更新接口,如果需要更新某个Key的值,只需要插入一条新纪录即可;或者先删除旧记录,再插入也可;
读操作流程:
1、在内存中依次查找memtable、immutable memtable;
2、如果配置了cache,查找cache;
3、根据mainfest索引文件,在磁盘中查找SST文件;
举个例子:我们先往levelDb里面插入一条数据 {key=“test” value=“我们”},过了几天,samecity网站改名为:69同城,此时我们插入数据{key=“test value=“他们”},同样的key,不同的value;逻辑上理解好像levelDb中只有一个存储记录,即第二个记录,但是在levelDb中很可能存在两条记录,即上面的两个记录都在levelDb中存储了,此时如果用户查询key=“test”,我们当然希望找到最新的更新记录,也就是第二个记录返回,因此,查找的顺序应该依照数据更新的新鲜度来,对于SSTable文件来说,如果同时在level L和Level L+1找到同一个key,level L的信息一定比level L+1的要新。
注意:Level 0的SSTable文件和其它Level的文件相比有特殊性:这个层级内的.sst文件,两个文件可能存在key重叠,比如有两个level 0的sst文件,文件A和文件B,文件A的key范围是:{bar, car},文件B的Key范围是{blue,samecity},那么很可能两个文件都存在key=”blood”的记录。对于其它Level的SSTable文件来说,则不会出现同一层级内.sst文件的key重叠现象,就是说Level L中任意两个.sst文件,那么可以保证它们的key值是不会重叠的
Rocksdb的SST文件合并
LSM-Tree保证了写操作在一次磁盘和一次内存写后就能返回,但在leveldb/rocksdb端后续处理上,还是有很多的工作,最重要的就是数据落盘后SST文件的合并处理;对于Leveldb来说,写入磁盘后的SStable文件会被分成多个不同的level,这也是leveldb名称的由来;leveldb/rocksdb的组织方式是,当某个level的文件数量或者总大小达到预设的值后,该level的一个文件(level0为所有文件)就会与下一层的文件发生合并,合并后的文件会进入下一个level,例如level0文件大小或数量达到阈值后就会与level1的文件发生合并,原来的level1的文件就可以安全删除了,当然,在合并的时候会进行去重和排序操作,这样就能保证每一层的数据都是有序的,此时的排序相当于N路归并排序。
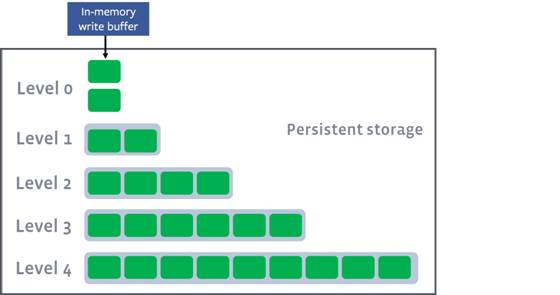
存储空间大小
其实对于ceph而言
write_buffer_size:单个memtable的大小,当memtable达到指定大小,会自动转换成immutable memtable并且新创建一个memtable(32M)
level0_file_num_compaction_trigger:L0达到指定个数的sstable后,触发compaction L0->L1。所以L0稳定状态下大小为write_buffer_size * min_write_buffer_number_to_merge * evel0_file_num_compaction_trigger(32 * 1 * 4 = 256M)(默认为4)
max_bytes_for_level_base:L1的总大小,L1的大小建议设置成和L0大小一致,提升L0->L1的compaction效率
min_write_buffer_number_to_merge:immutable memtable在flush之前先进行合并,比如参数设置为2,当一个memtable转换成immutable memtable后,RocksDB不会进行flush操作,等到至少有2个后才进行flush操作。这个参数调大能够减少磁盘写的次数,因为多个memtable中可能有重复的key,在flush之前先merge后就避免了旧数据刷盘;但是带来的问题是每次数据查找,当memtable中没有对应数据,RocksDB可能需要遍历所有的immutable memtable,会影响读取性能
max_bytes_for_level_base:L1的总大小,L1的大小建议设置成和L0大小一致,提升L0->L1的compaction效率(256M)
max_bytes_for_level_multiplier:当前与下一层空间大小比例系数(10)
num_levels:文件最大层数(包括level 0),默认值为7
空间放大问题
空间放大是rocksdb几乎逃避不了的问题,假设某业务场景如下:
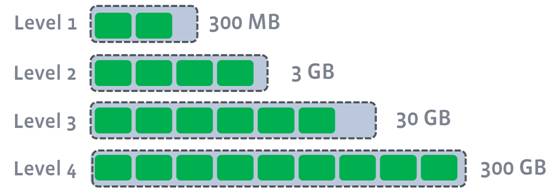
keys总数恒定,每天会全量更新所有keys DB 大小恒定,所有key-value一共28G 以rocksdb默认配置来分析,每一层大小限制如下:
Level 1 —> 256M
Level 2 —> 2.56G
Level 3 —> 25.6G
Level 4 —> 256G
…
如果要求空间放大为0,即rocksdb中都是有效数据,则应该在全量更新数据后,Level 0 到 Level 3每一层都为0,28G数据全部都在Level 4,如下:
Level 1 —> 0M
Level 2 —> 0M
Level 3 —> 0M
Level 4 —> 28G
…
而想要达到这样的结果,则应该在某次全量更新结束后执行CompactRange来主动进行全局Compaction,此时空间放大为0,十分理想 第二天同样继续来一波28G的全量更新,如果不强制执行compactRange,那此时每一层的大小有可能是这样:
Level 1 —> 250M
Level 2 —> 2.55G
Level 3 —> 25.2G
Level 4 —> 28G (前一天的全量数据)
此时rocksdb刚好有两天的全量数据,Level 1 到 Level 3 总和28G是今天的,Level 4的28G是昨天的,此时写放大是(28G + 28G) / 28G = 2,整整多占了一倍的磁盘空间,并且AutoCompaction无能为力,我们明知道如果将Level 1 到 Level 3的数据推到Level 4,则昨天的数据会全部被Drop掉,只剩下今天的数据在Level 4,磁盘占用会才从56G减少到28G,但按照rocksdb默认的compaction策略,Level 1到 Level 3都没有达到触发AutoCompaction的大小。 怎么解决呢,我们知道rocksdb默认是base_level是Level 1,大小上限是256M,然后每一层大小上限基于此乘以10,依次往下,对于上述情况,能否改变思路,不要从上往下来定每一层的大小上限,而是从下往上来定,这样倒着搞更有利于整体保持正三角的形状,而正三角的写放大差不多是1.1111,还是十分理想的。
level_compaction_dynamic_level_bytes
如果打开level_compaction_dynamic_level_bytes,则base_level会从默认的Level 1 变成最高层 Level 6,即最开始Level 0会直接compact到Level 6,如果某次compact后,Level 6大小超过256M(target_file_size_base),假设300M,则base_level向上调整,此时base_level变成Level 5,而Level 5的大小上限是300M/10 = 30M,之后Level 0会直接compact到Level 5,如果Level 5超过30M,假设50M,则需要与Level 6进行compact,compact后,Level 5恢复到30M以下,Level 6稍微变大,假设320M,则基于320M继续调整base_level,即Level 5的大小上限,调整为320M/10 = 32M,随着写入持续进行,最终Level 5会超过256M(target_file_size_base),此时base_level需要继续上调,到Level 4,取Level 5和Level 6当前大小较大者,记为MaxSize,则Level 4的大小上限为MaxSize/100,Level 5的大小上限为Level 4大小上限乘以10,依次类推。
就像上述举例中:当数据压缩到28G时,上一层大小限制是2.8G,再上一层也就是0.28G,显然不会出现L3为25G这种情况,早就触发了compact,从而避免了太多的空间放大。
在rocksdb中:每次base_level及其大小上限(base_bytes)的调整发生在LogAndApply之后,根据当前每一层的现状来进行调整,实现逻辑在VersionStorageInfo::CalculateBaseBytes()中,大致过程如下:
从first_non_empty_level到最后一层,统计每一层的大小,找出最大者,记为max_level_size,最大者不一定是最后一层,因为有可能在某次compaction后,其他层的大小会大于最后一层 从倒数第二层往上到first_non_empty_level,假设有n层,则cur_level_size = max_level_size/(10^n),cur_level_size是当前first_non_empty_level的新的大小上限 如果cur_level_size > max_bytes_for_level_base(256M),则对cur_level_size除以10继续向上调整first_non_empty_level,直到调整到某一层,cur_level_size <= max_bytes_for_level_base(256M),此时该层为新的base_level,即新的first_non_empty_level,base_size为cur_level_size 然后从base_level开始,往下,每一层对base_size乘以10,当做该层新的大小限制

如果在ceph异常场景恢复过程中,更容易理解空间大小分配
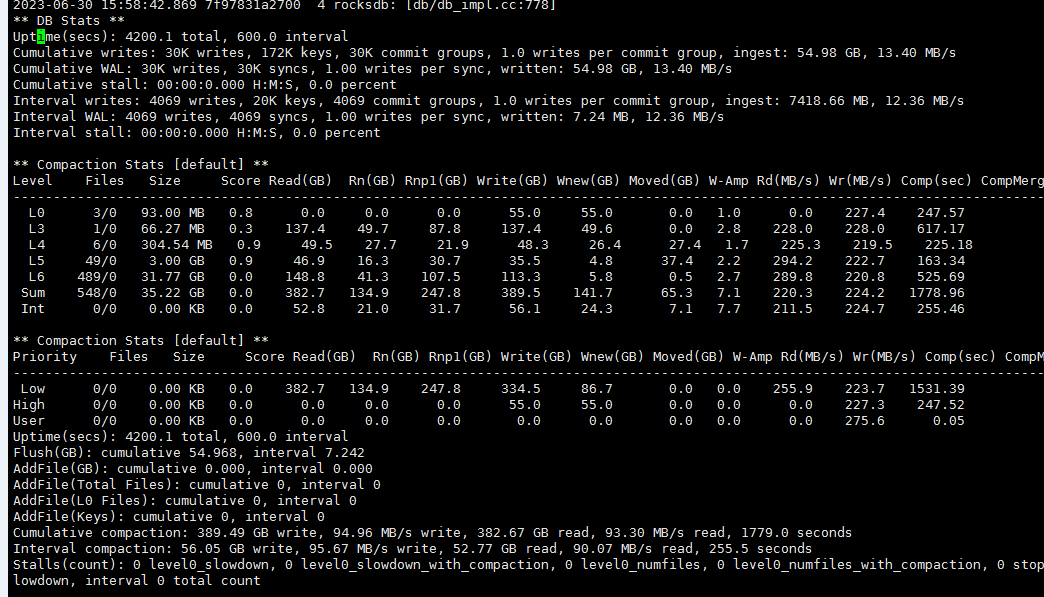
rocsdb 数据读取
可以利用ceph-kvstore-tool从rocksdb查看管理数据
注:需要停ceph-mon服务,或者将当前mon数据库复制到其他地方,然后进行读取
-
看到所有的prefix以及key
ceph-kvstore-tool rocksdb /var/lib/ceph/mon/ceph-3/store.db/ list 可以看到所有的prefix以及key
-
根据prefix以及key导出具体的数据
ceph-kvstore-tool rocksdb /var/lib/ceph/mon/ceph-3/store.db/ get paxos 456221 out /etc/ceph/paxos_456221
-
导出所有的key
ceph-monstore-tool /var/lib/ceph/mon/ceph-3/ dump-keys > /home/1.txt
-
根据数据库名称导出所有值
ceph-kvstore-tool rocksdb /var/lib/ceph/mon/ceph-3/store.db/ dump logm > /home/logm
更多的功能可以help下
导出的数据为encode的数据
用工具ceph-dencoder查看导出的内容
ceph-dencoder的type类型很多,可以用ceph-dencoder list_types查看
其中paxos:MonitorDBStore::Transaction,osd_full:OSDMap,osd:OSDMap::Incremental
例如
ceph-kvstore-tool rocksdb /var/lib/ceph/mon/ceph-3/store.db/ get paxos 456221 out /etc/ceph/paxos_456221
ceph-dencoder type MonitorDBStore::Transaction import /etc/ceph/paxos_456221 decode dump_json
{
"transaction": {
"ops": [
{
"op_num": 0,
"type": "PUT",
"prefix": "logm",
"key": "full_292111",
"length": 24085
},
{
"op_num": 1,
"type": "PUT",
"prefix": "logm",
"key": "full_latest",
"length": 8
},
{
"op_num": 2,
"type": "PUT",
"prefix": "logm",
"key": "292112",
"length": 724
},
{
"op_num": 3,
"type": "PUT",
"prefix": "logm",
"key": "last_committed",
"length": 8
}
],
"num_keys": 4,
"num_bytes": 25001
}
}
参考(转载)文档: