ceph monitor paxos算法
对于分布式来说最重要的莫过于所有副本数据的一致性。
在monitor节点中,存在着Leader和Peon两种角色。当客户端发出读命令时可以由相应的Peon或者Leader返回。一旦发生修改动作,所有的消息会第一时间发送给Leader节点,然后由Leader节点分发给Peon节点。
paxos算法保证了一次修改操作只能批准一个值,从而保证了分布式系统副本的一致性。
多个节点之间存在两种通讯模型:共享内存(Shared memory)、消息传递(Messages passing),Paxos是基于消息传递的通讯模型的。
paxos转换时机
1.monitor启动时,paxos初始化;
2.monitor进入bootstrap,判断是否需要同步数据,然后触发选举;
3.monitor根据选举结果,paxos对应初始化为leader或peon;
4.monitor进入recovery状态(monitor异常时也会触发);
5.monitor运行过程中,paxos决议;
paxos的同步数据过程
每次monitor server启动时都会按照monmap中的服务器地址去连接其他monitor服务器,看下是否需要同步数据。这个过程叫做bootstrap(). bootstrap的第一个目的是补全数据,从其他服务拉缺失的paxos log或者全量复制数据库,其次是在必要时形成多数派建立一个paxos集群或者加入到已有的多数派中。

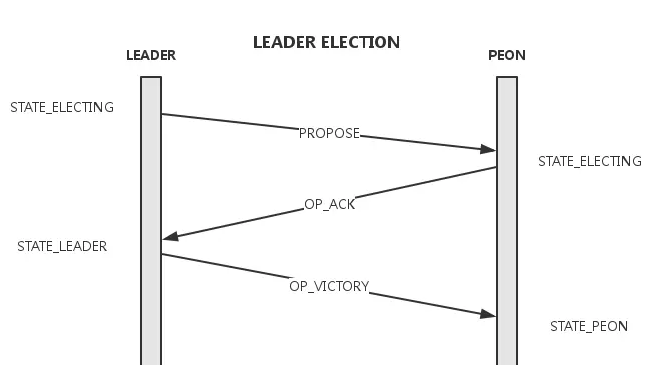
选主
- 将election_epoch加1,向Monmap中的所有其他节点发送Propose消息;
- 收到Propose消息的节点进入election状态并仅对有更新的election_epoch且rank值大于自己的消息答复Ack。这里的rank简单的由ip大小决定;
- 发送Propose的节点统计收到的Ack数,超时时间内收到Monmap中大多数的ack后可进入victory过程,这些发送ack的节点形成quorum;
victory
- election_epoch加1,可以看出election_epoch的奇偶可以表示是否在选举轮次;
- 向quorum中的所有节点发送VICTORY消息,并告知自己的epoch及quorum;
- 当前节点完成Election,进入Leader状态;
- 收到VICTORY消息的节点完成Election,进入Peon状态
paxos的recovery过程
目的是就PN达成一致,包括三个步骤,如下: 
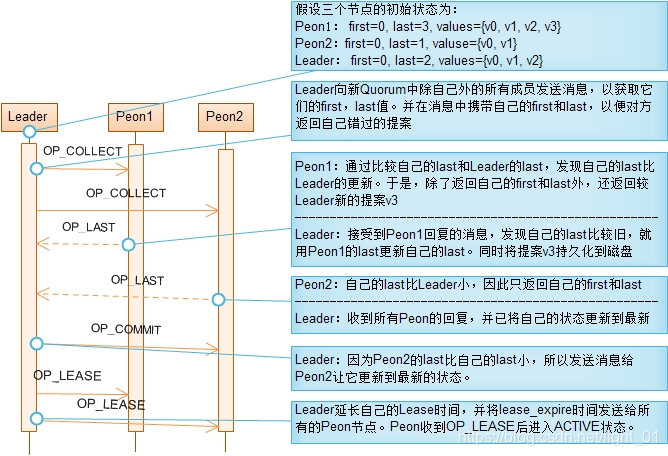
在Leader选举成功后,Leader和Peon都进入Recovery阶段。该阶段的目的是为了保证新Quorum的所有成员状态一致,这些状态包括:最后一个批准(Committed)的提案,最后一个没批准的提案,最后一个接受(Acceppted)的提案。每个节点的这些状态都持久化到磁盘。对旧Quorum的所有成员来说,最后一个通过的提案应该都是相同的,但对不属于旧Quorum的成员来说,它的最后一个通过的提案是落后的。
同步已批准提案的方法是,Leader先向新Quorum的所有Peon节点发送OP_COLLECT消息,并在消息中携带Leader自己的第1个和最后1个批准的提案的值的版本号。Peon收到OP_COLLECT消息后,将自己的第1个和最后1个批准的提案的值的版本号返回给Leader,并且如果Peon的最后1个批准的版本号大于Leader最后一个批准的版本号时,将所有在大于Leader最后一个版本号的提案值发送给Leader。Leader将根据这些信息填补自己错过的提案。这样,当Leader接收到所有Peon对OP_COLLECT消息的回应后,也就将自己更新到了最新的状态。这时Leader又反过来将最新状态同步到其它节点。
为获取新Quorum所有成员中的最大提案号,Leader在发送OP_COLLECT消息时,提出它知道的最大的提案号,并将该提案号附加在OP_COLLECT消息中。如果Peon已接受的最大提案号大于Leader提出的提案号,则拒绝接受Leader提出的提案号并将自己已接受的最大提案号通过OP_LAST消息发送给Leader。Leader收到OP_LAST消息后,发现自己的提案号不是最大时,就在Peon接受的最大提案号的基础上提出更大的提案号,重新进入Recovery阶段。这样,最终可以获取到最大的提案号。
总而言之,Recovery阶段的目的是让新Quorum中所有节点处于一致状态。实现这一目的的方法分成两步: 首先,在Leader节点收集所有节点的状态,通过比较得到最新状态; 然后,Leader将最新状态同步给其它节点。有两个比较重要的状态,最后一次批准的提案和已接受的最大提案号。
注意 区分提案号(proposal number)、提案值(value)、提案值的版本号(value version) 这三个概念。提案号由Leader提出,为避免不同Leader提出的提案号不冲突,同个Leader提出的提案号是不连续的。提案的值的版本号是连续的。
paxos的propose过程
即正常工作过程中的Propose、accept和commit过程。 
从begin()到commit_finish()称为一轮,即一次提议的完成过程。
串行化提议:
Ceph的paxos实现,每次只允许一个提议在执行中,即上面提到 的一轮完成才能执行下一轮。在这个过程中,会有多次写盘操作。
这个过程实际上比较慢。对于ceph自身来说,osd等的状态变更, 不频繁,无需极高的paxos性能。 但是如果用于做用于分布式数据库等系统的日志,这种方式则有不足。

何时需要发起提案Proposal
Paxos的Trigger点总是要发起提案,那么ceph中需要发起提案的地方,大抵有以下三种:
- ConfigKeyService在修改或删除key/value对的时候
- Paxos以及PaxosService对数据做trim的时候,trim的目的是为了节省rocksdb存储空间,参见Paxos::trim和PaxosService::maybe_trim
- PaxosService的各种服务更新值
PaxosService更新log为例
客户端发来修改请求到底是个什么过程呢?
其他需要monitor协作的模块构建与mon通讯的对象,然后发送消息给mon: monc->send_mon_message(m);
monitor收到消息后,进入Monitor::handle_forward()
Monitor::handle_forward() -->_ms_dispatch-->dispatch_op-->PaxosService.cc:dispatch-->propose_pending-->paxos->trigger_propose();-->propose_pending-->begin(bl);
发起提案
begin:
// note which pn this pending value is for.
设置pending_pn以及pending_v
t->put(get_name(), "pending_v", last_committed + 1);
t->put(get_name(), "pending_pn", accepted_pn);
...
//将transaction写入rocksdb
get_store()->apply_transaction(t);
....
//设置last_committed等
begin->values[last_committed+1] = new_value;
begin->last_committed = last_committed;
begin->pn = accepted_pn;
...
//通知其他monitor决议
mon->send_mon_message(begin, *p);
提案的内容可以利用ceph-kvstore-tool从rocksdb中看到
ceph-kvstore-tool rocksdb /var/lib/ceph/mon/ceph-3/store.db/ get paxos 456221 out /etc/ceph/paxos_456221
然后用ceph-dencoder查看相关内容
ceph-dencoder type MonitorDBStore::Transaction import /etc/ceph/paxos_456221 dump_json
{
"transaction": {
"ops": [
{
"op_num": 0,
"type": "PUT",
"prefix": "logm",
"key": "full_292111",
"length": 24085
},
{
"op_num": 1,
"type": "PUT",
"prefix": "logm",
"key": "full_latest",
"length": 8
},
{
"op_num": 2,
"type": "PUT",
"prefix": "logm",
"key": "292112",
"length": 724
},
{
"op_num": 3,
"type": "PUT",
"prefix": "logm",
"key": "last_committed",
"length": 8
}
],
"num_keys": 4,
"num_bytes": 25001
}
}
peon决议之后会将返回给leader
// peon
void Paxos::handle_begin(MonOpRequestRef op)
{
op->mark_paxos_event("handle_begin");
MMonPaxos *begin = static_cast<MMonPaxos*>(op->get_req());
dout(10) << "handle_begin " << *begin << dendl;
// can we accept this?
if (begin->pn < accepted_pn) {
dout(10) << " we accepted a higher pn " << accepted_pn << ", ignoring" << dendl;
op->mark_paxos_event("have higher pn, ignore");
return;
}
...
t->put(get_name(), v, begin->values[v]);
// note which pn this pending value is for.
t->put(get_name(), "pending_v", v);
t->put(get_name(), "pending_pn", accepted_pn);
...
auto start = ceph::coarse_mono_clock::now();
get_store()->apply_transaction(t);
auto end = ceph::coarse_mono_clock::now();
...
// reply 接受之后返回通知leader
MMonPaxos *accept = new MMonPaxos(mon->get_epoch(), MMonPaxos::OP_ACCEPT,
ceph_clock_now());
accept->pn = accepted_pn;
accept->last_committed = last_committed;
begin->get_connection()->send_message(accept);
}
leader接收accept消息,执行commit
主接受accept消息处理
// leader
void Paxos::handle_accept(MonOpRequestRef op)
{
op->mark_paxos_event("handle_accept");
//提交commit
if (accepted == mon->get_quorum()) {
// yay, commit!
dout(10) << " got majority, committing, done with update" << dendl;
op->mark_paxos_event("commit_start");
commit_start();
}
commit_start中将lastcommit+1
// commit locally
t->put(get_name(), "last_committed", last_committed + 1);
/*让事务生效,注意,此处是异步掉用*/
get_store()->queue_transaction(t, new C_Committed(this));
//此处事务的处理,是异步的,掉用了MonitorDBStore的queue_transaction函数。当事务完成之后,会掉用相关的回调函数。
leader执行回调
void queue_transaction(MonitorDBStore::TransactionRef t,
Context *oncommit) {
io_work.queue(new C_DoTransaction(this, t, oncommit));
}
执行回调C_Committed
struct C_Committed : public Context {
Paxos *paxos;
explicit C_Committed(Paxos *p) : paxos(p) {}
void finish(int r) override {
ceph_assert(r >= 0);
std::lock_guard l(paxos->mon->lock);
if (paxos->is_shutdown()) {
paxos->abort_commit();
return;
}
paxos->commit_finish();
}
};
//commit_finish中会处理last_committed++;以及通知其他mon,然后执行refresh
// tell everyone
for (set<int>::const_iterator p = mon->get_quorum().begin();
p != mon->get_quorum().end();
++p) {
if (*p == mon->rank) continue;
dout(10) << " sending commit to mon." << *p << dendl;
MMonPaxos *commit = new MMonPaxos(mon->get_epoch(), MMonPaxos::OP_COMMIT,
ceph_clock_now());
commit->values[last_committed] = new_value;
commit->pn = accepted_pn;
commit->last_committed = last_committed;
mon->send_mon_message(commit, *p);
...
if (do_refresh()) {
commit_proposal();
if (mon->get_quorum().size() > 1) {
//延长租约,会发送mon->send_mon_message(lease, *p);到其他mon
extend_lease();
}
ceph_assert(g_conf()->paxos_kill_at != 10);
finish_round();
}
}
peon接收后存放数据,并执行refresh
void Paxos::handle_commit(MonOpRequestRef op)
{
op->mark_paxos_event("handle_commit");
MMonPaxos *commit = static_cast<MMonPaxos*>(op->get_req());
dout(10) << "handle_commit on " << commit->last_committed << dendl;
logger->inc(l_paxos_commit);
if (!mon->is_peon()) {
dout(10) << "not a peon, dropping" << dendl;
ceph_abort();
return;
}
op->mark_paxos_event("store_state");
store_state(commit);
(void)do_refresh();
}
接受延长lease的处理
// peon
void Paxos::handle_lease(MonOpRequestRef op)
并且peon的状态从updating转变成active
do_refresh会调动各种paxos服务执行update_from_paxos
do_refresh--> mon->refresh_from_paxos-->svc->refresh(need_bootstrap)->update_from_paxos;svc->post_refresh();
svc即是具体的各种paxos服务
不同的实现类对update_from_paxos的处理不一样
void LogMonitor::update_from_paxos(bool *need_bootstrap)
{
dout(10) << __func__ << dendl;
version_t version = get_last_committed();
dout(10) << __func__ << " version " << version
<< " summary v " << summary.version << dendl;
if (version == summary.version)
return;
ceph_assert(version >= summary.version);
map<string,bufferlist> channel_blog;
version_t latest_full = get_version_latest_full();
dout(10) << __func__ << " latest full " << latest_full << dendl;
if ((latest_full > 0) && (latest_full > summary.version)) {
bufferlist latest_bl;
get_version_full(latest_full, latest_bl);
ceph_assert(latest_bl.length() != 0);
dout(7) << __func__ << " loading summary e" << latest_full << dendl;
auto p = latest_bl.cbegin();
decode(summary, p);
dout(7) << __func__ << " loaded summary e" << summary.version << dendl;
}
// walk through incrementals
while (version > summary.version) {
bufferlist bl;
int err = get_version(summary.version+1, bl);
ceph_assert(err == 0);
ceph_assert(bl.length());
auto p = bl.cbegin();
__u8 v;
decode(v, p);
while (!p.end()) {
//写入logm full
summary.add(le);
}
summary.version++;
//根据配置更新每个channel下的日志记录(删除old),默认配置为50条
summary.prune(g_conf()->mon_log_max_summary);
}
dout(15) << __func__ << " logging for "
<< channel_blog.size() << " channels" << dendl;
for(map<string,bufferlist>::iterator p = channel_blog.begin();
p != channel_blog.end(); ++p) {
...
//根据channel写入不同的文件(例如ceph-mon,ceph-audit.log等)
int err = p->second.write_fd(fd);
}
check_subs();
}
ceph-kvstore-tool rocksdb /var/lib/ceph/mon/ceph-3/store.db/ get logm full_292111 out /etc/ceph/logm_full_292111
ceph-dencoder type LogSummary import/etc/ceph/logm_full_292111 dump_json
logm / full_292112 记录的logsummury的内容,这个里面有诸多的LogEntry,而这次提案中logm / 292112保存的是单个的log entity
{
"version": 292112,
"tail_by_channel": {
"": {
"1": {
"name": "mon.ceph-1",
"rank": "mon.0",
"addrs": {
"addrvec": [
{
"type": "v2",
"addr": "10.0.204.93:3300",
"nonce": 0
},
{
"type": "v1",
"addr": "10.0.204.93:6789",
"nonce": 0
}
]
},
"stamp": "2023-07-03 10:01:21.142025",
"seq": 0,
"channel": "",
"priority": "[INF]",
"message": "mkfs 1a031b5a-b249-41d2-b30b-4076d1c6c32d"
}
},
"audit": {
"40823867": {
"name": "mon.ceph-3",
"rank": "mon.2",
"addrs": {
"addrvec": [
{
"type": "v2",
"addr": "10.0.204.94:3300",
"nonce": 0
},
{
"type": "v1",
"addr": "10.0.204.94:6789",
"nonce": 0
}
]
},
"stamp": "2023-07-12 14:25:39.471472",
"seq": 2,
"channel": "audit",
"priority": "[DBG]",
"message": "from='client.? 10.0.204.94:0/4002593326' entity='client.admin' cmd=[{\"prefix\": \"health\"}]: dispatch"
},
其中292112对应的值即是一个LogEntry
osdmap与此类似
osdmap / 1657 记录本次要变化的osdmap
osdmap / full_1657 记录的是全量的osdmap内容
update_from_paxos之后会根据osdmap / 1657 以及osdmap全量数据更新为osdmap / full_1657
参考(转载)文档: